上一篇我們對 Compute Shader有了基本的認識 ,今天把觀念補齊:
工作群組(Workgroup) 怎麼分工?同步(Barrier) 在避免資料競爭扮演什麼角色?共享記憶體(var<workgroup>) 為何能讓效能暴衝?最後給你一份效能小抄,讓你的 WebGPU 計算從「能跑」變成「跑很快」。
先用一個好懂的「工地」比喻:
@workgroup_size(x,y,z) 決定「每隊幾個人」。@builtin(workgroup_id)):第幾隊。@builtin(local_invocation_id)):隊內第幾號工人。@builtin(global_invocation_id)):把「第幾隊 × 每隊人數 + 隊內編號」合起來的全場編號。常用來對資料做索引。口訣:幾隊(dispatch) × 每隊人數(workgroup_size) = 這次總執行緒數。
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3<u32>,
@builtin(workgroup_id) g : vec3<u32>,
@builtin(local_invocation_id) lid : vec3<u32>) {
// gid.x → 這個人要處理的「全域」資料索引
// g.x → 我是第幾隊
// lid.x → 我在隊內的編號(0..63)
}
多個執行緒「一起寫同一塊資料」會產生資料競爭(race condition)。
Barrier(柵欄) 讓所有執行緒在關鍵點「等彼此」,並且保證前面的寫入,後面看得到。
在 WGSL 裡有兩種柵欄(只在同一個 workgroup 之內有效):
workgroupBarrier():執行緒同步 + workgroup 記憶體(var<workgroup>)的可見性同步。
storageBarrier():針對 Storage(SBO) 的可見性同步。
注意:沒有跨 workgroup 的 Barrier。如果你需要「全場一起同步」,做法是分多個 pass(先寫、再讀)。
var<workgroup>:GPU 上的「超快暫存區」workgroupBarrier() 等齊 → 在這塊快取裡做多輪運算 → 只把結果寫回 Storage。device.limits.maxComputeWorkgroupStorageSize,常見 ~32KB)。陣列大小必須是常數。在CPU端建立一個陣列存放1~10,並塞入GPU buffer中。
執行compute shader,將每個元素乘以2後寫回。
async function initWebGPU() {
if (!navigator.gpu) {
console.error("WebGPU is not supported in this browser.");
return;
}
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
const canvas = document.querySelector('canvas');
const context = canvas.getContext('webgpu');
const shaderCode = `
@group(0) @binding(0) var<storage, read_write> data: array<u32>;
@compute @workgroup_size(1)
fn main(@builtin(global_invocation_id) global_id : vec3<u32>) {
let index = global_id.x;
data[index] = data[index] * 2;
}
`;
//==============================
// Buffer
//==============================
const storageBuffer = device.createBuffer({
size: 4 * 10, // a 32 bit uint
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC,
});
const initialData = new Uint32Array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]);
device.queue.writeBuffer(storageBuffer, 0, initialData);
//===============================
// Binding
//===============================
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: { type: 'storage' },
},
],
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: storageBuffer,
},
},
],
});
//===============================
// Pipeline
//===============================
const shaderModule = device.createShaderModule({
code: shaderCode,
});
const pipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module: shaderModule,
entryPoint: "main",
},
});
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(10, 1, 1);
passEncoder.end();
const commandBuffer = commandEncoder.finish();
device.queue.submit([commandBuffer]);
console.log("Compute shader executed.");
}
initWebGPU();
準備一個
COPY_DST的buffer裝寫出的資料,再用console.log print出來。
const debug_size = 10;
const _data_size = 4; // size of int
const _buffer_size = debug_size * _data_size;
const buffer = storageBuffer;
const readBuffer = device.createBuffer({
size: _buffer_size,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
label: "read back buffer"
});
const _cmdPass = device.createCommandEncoder();
_cmdPass.copyBufferToBuffer(buffer, 0, readBuffer, 0, _buffer_size);
device.queue.submit([ _cmdPass.finish()]);
console.log("=============== Read Back =================");
readBuffer.mapAsync(GPUMapMode.READ).then(() => {
const result = new Uint32Array(readBuffer.getMappedRange());
for(var i = 0 ; i < debug_size ;i++ ){
console.log(result[i]);
}
readBuffer.unmap();
});
成果: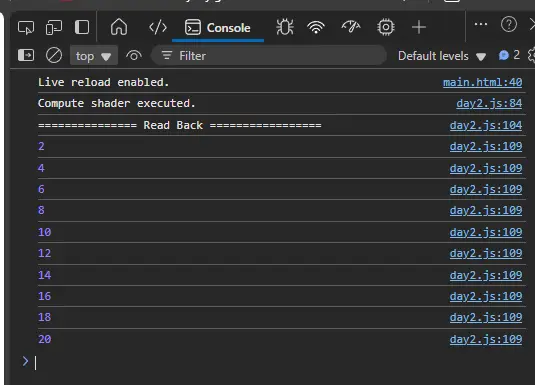
查限制:device.limits.maxComputeWorkgroupSizeX/Y/Z、maxComputeInvocationsPerWorkgroup(常見 256 或 1024)、maxWorkgroupsPerDimension、maxComputeWorkgroupStorageSize。
穩健的起點:
@workgroup_size(64) 或 128。@workgroup_size(8,8)、(16,16)(看 workgroup 記憶體大小)。調整原則:
maxComputeWorkgroupStorageSize。在 JS/TS 端印出限制(快速檢查):
console.table({
maxWGSizeX: device.limits.maxComputeWorkgroupSizeX,
maxWGSizeY: device.limits.maxComputeWorkgroupSizeY,
maxWGSizeZ: device.limits.maxComputeWorkgroupSizeZ,
maxInvocations: device.limits.maxComputeInvocationsPerWorkgroup,
maxWGStorage: device.limits.maxComputeWorkgroupStorageSize
});
i = global_id.x,相鄰執行緒讀相鄰元素(coalesced)。vec4<f32> 等 16-byte 對齊的結構(特別在 Storage Buffer)。vec3(以 vec4 取代或 @align(16))。maxComputeInvocationsPerWorkgroup。var<workgroup>,用 workgroupBarrier() 把每輪運算切段。queue.writeBuffer。performance.now() 包 queue.submit() + await device.queue.onSubmittedWorkDone() 做粗略時間。workgroupBarrier() 或誤用 storageBarrier();或多執行緒同時寫同一格沒有用 atomic。global_id 沒做越界檢查。maxComputeWorkgroupStorageSize;一次 dispatch 的維度超過 maxWorkgroupsPerDimension。

 iThome鐵人賽
iThome鐵人賽